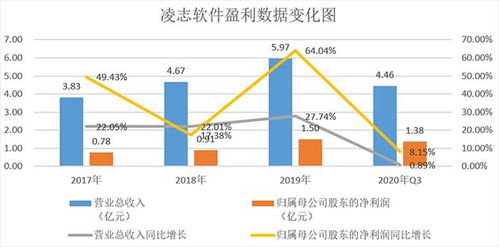
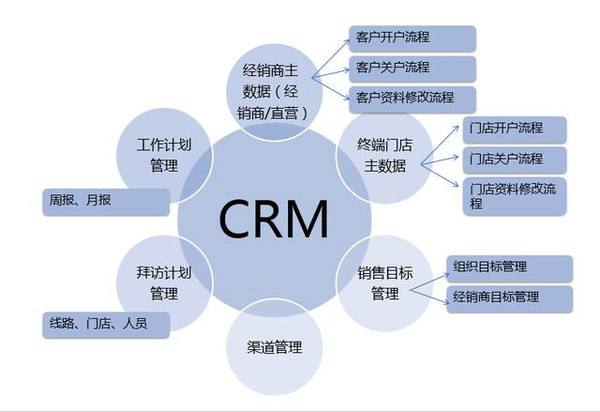
四川成都智慧農(nóng)政管理系統(tǒng),智慧農(nóng)業(yè)oa辦公系統(tǒng)(重慶,貴州)|oa辦公
更新時(shí)間:2026-04-30 23:20:10
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.zenjoy.cn/product/71.html
PRODUCT
產(chǎn)品列表
-
更新時(shí)間:2026-04-30 20:55:47
更新時(shí)間:2026-04-30 23:20:10
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.zenjoy.cn/product/71.html
PRODUCT
產(chǎn)品列表
更新時(shí)間:2026-04-30 20:55:47